
data engineering
consulting
what is data engineering?
advantages of data engineering
reliability
Data engineering ensures your data is accurate, consistent, and trustworthy. When the foundation is solid, every dashboard and analysis built on top of it delivers real value.scalability
Well-designed data pipelines handle growing volumes of information without breaking. This means your systems stay fast and reliable as your organization expands.integration
Data engineering connects information from different systems — cloud, on-prem, or third-party — into one place. This unified view makes decision-making easier and faster.flexibility
With strong data engineering, your data is modeled in a way that adapts to new needs. Whether it’s a new dashboard, platform, or tool, your data is ready to support it.which data engineering ecosystem is best?

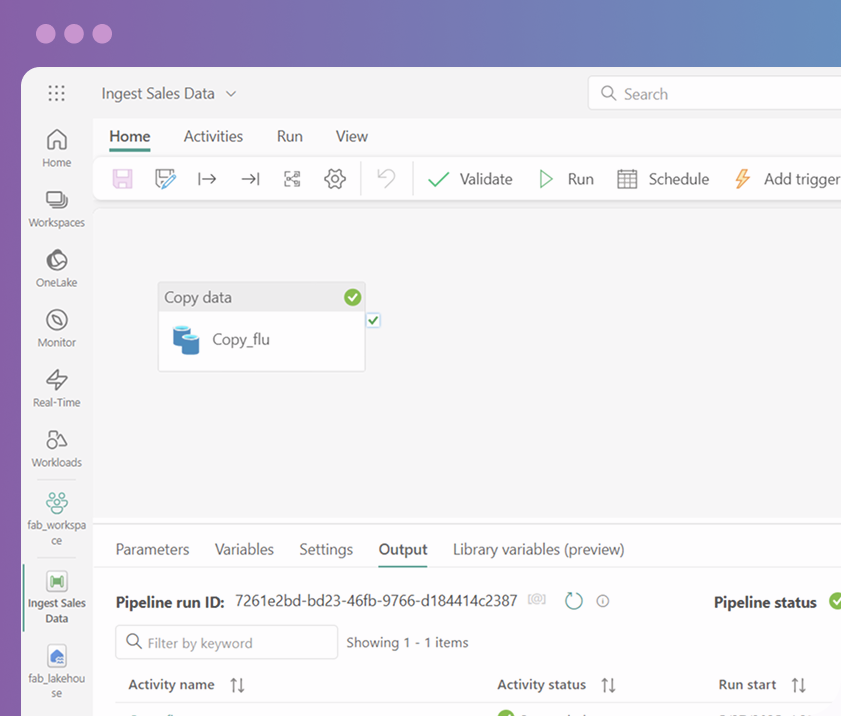
NEW: Microsoft Fabric
 unified platform
seamless integration
scalability and performance
unified platform
seamless integration
scalability and performance
ready to start?
let's talk
frequently asked questions
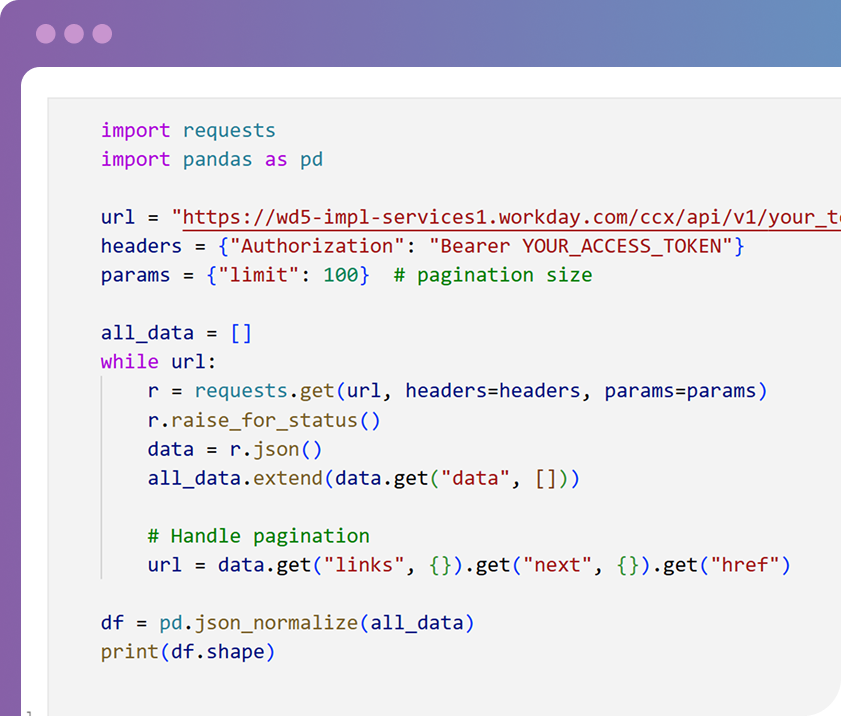
It's a lot of things. Data engineering can contain parts of data collection (via APIs, web scraping, etc.), data cleaning (such as removing duplicates or ensuring ISO standards), data transformation (such as introducing calculated fields or joining with other data) and more.
We are a Microsoft Partner, so we are most used to the Microsoft ecosystem, which is Azure and Fabric. However, if you're already using AWS, GCP, Snowflake or another tool, we can still make it work.
Sure. If you have specific changes in mind, we can introduce them to existing code. If you're unsure about what your data engineering pipeline needs to comply with your new business logic, we can work it out together.
Yes. By the end of the project, you will have full access to and ownership of any code we write. You will also receive full documentation if needed.