
data engineering
konsulenter til 525 kr. i timen
hvad er data engineering?
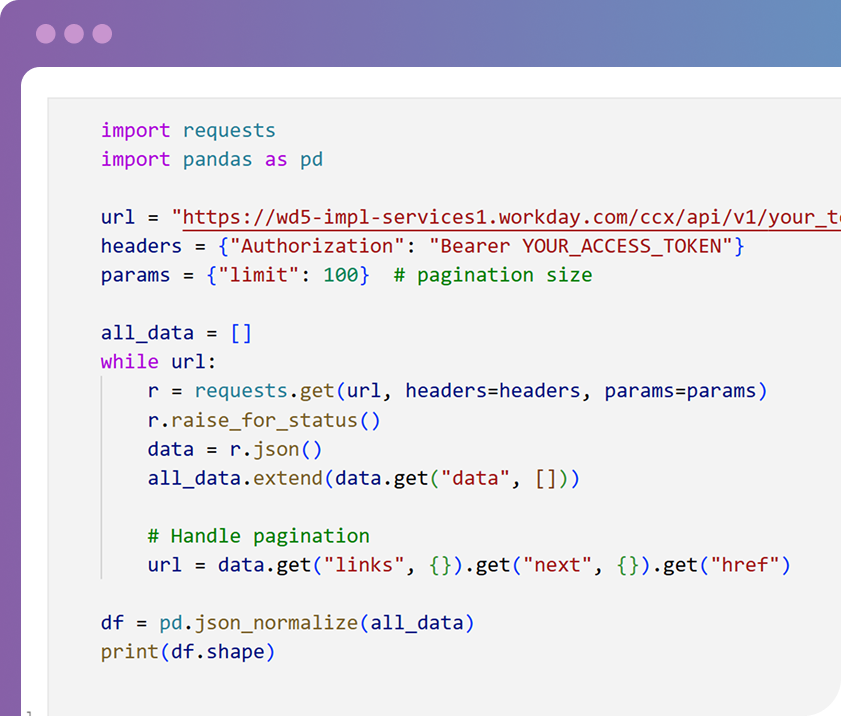
fordele ved data engineering
pålidelighed
Data engineering sikrer, at jeres data er nøjagtige, konsistente og troværdige. Når fundamentet er solidt, leverer hvert dashboard og hver analyse reel værdi.skalerbarhed
Veludformede datapipelines kan håndtere stigende datamængder uden at bryde sammen. Det betyder, at jeres systemer forbliver hurtige og stabile, efterhånden som organisationen vokser.integration
Data engineering forbinder data fra forskellige systemer — cloud, on-prem eller tredjepart — i ét samlet overblik. Denne helhed gør beslutningstagning enklere og hurtigere.fleksibilitet
Med stærk data engineering bliver jeres data modelleret på en måde, der kan tilpasse sig nye behov. Uanset om det gælder et nyt dashboard, en ny platform eller et nyt værktøj, er dataene klar til at understøtte det.hvilket data engineering-økosystem er bedst?

NYHED: Microsoft Fabric
 samlet platform
sømløs integration
skalerbarhed og ydeevne
samlet platform
sømløs integration
skalerbarhed og ydeevne
klar til at komme i gang?
lad os tage en snak
ofte stillede spørgsmål
Det er mange ting. Data engineering kan omfatte dele af dataindsamling (via API’er, web scraping osv.), datarensning (fx fjernelse af dubletter eller sikring af ISO-standarder), datatransformation (fx beregnede felter eller sammenkobling med andre data) og mere.
Vi er Microsoft-partner og arbejder derfor mest i Microsoft-økosystemet, dvs. Azure og Fabric. Men hvis I allerede bruger AWS, GCP, Snowflake eller et andet værktøj, kan vi også få det til at fungere.
Selvfølgelig. Hvis I har specifikke ændringer i tankerne, kan vi implementere dem i den eksisterende kode. Hvis I er i tvivl om, hvad jeres data engineering-pipeline skal opfylde for at matche jeres nye forretningslogik, finder vi ud af det sammen.
Ja. Ved projektets afslutning får I fuld adgang til og ejerskab over al kode, vi skriver. I får også fuld dokumentation, hvis det er nødvendigt.